Will Critchlow and Britney Muller recently put out a piece at SearchPilot called “LLMs do not rank anything. So what are you optimizing for?”. The underlying implications of what this means for “AI Optimization” has been bouncing around in my head for a couple of weeks. It was the perfect inspiration for me to finally frame my perspective into something that I hope effectively conveys how I currently see opportunities for influencing LLMs for brands and clients.
If you want your brand to appear in AI-generated answers, you need to know where those answers actually come from. Most of the AI-visibility advice circulating right now treats the model as a single black box and offers one playbook. Usually it’s some flavor of “make great content” or “get cited on Reddit.” Both of those can be right. They can also be optimizing two completely different things, and confusing the two is how budgets get spent in the wrong place.
A baseline point first, and Britney has been one of the clearest voices on this: LLMs don’t rank anything. There’s no internal scoreboard mapping queries to documents. We’re not trying to land at position #1 on a list. We’re trying to influence the probability that a model says something useful about us when it produces text. That changes how we view which levers we can actually pull to create impact.
At a basic level, there are two mechanisms an LLM uses to produce an answer. They behave differently, they break differently, and they reward different kinds of work.
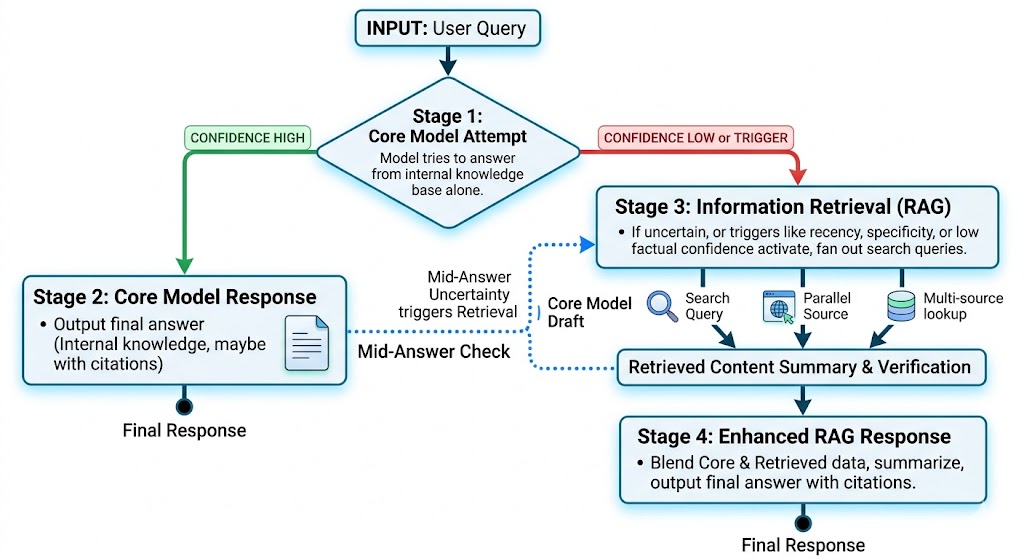
How an LLM Actually Builds an Answer
When you send a prompt, the model is drawing from two primary sources.
The first is the Core Model. This is the “memory” baked into the AI during training. It’s what the model knows on its own, without looking anything up: the compression of whatever corpus it was trained on. The Core Model gets rebuilt every time a new model version ships. You don’t write to it directly. You influence what gets included next time it’s rebuilt.
(Britney’s framing is more precise than mine on this, and worth borrowing. The model is a continuation engine, and what it actually learns is co-occurrence: which words, brands, and concepts appear alongside which others. “Memory” is the gateway analogy. Co-occurrence is what’s encoded.)
The second source is Retrieval. This is when the model goes out and fetches something at query time. It might visit a page, run a search, or pull from a recent cache. Whatever it gets back gets handed to the model to summarize in the context of your prompt.
The Generation Flow
The process generally looks like this:
- The model tries to answer from the Core Model alone.
2. If it can answer with confidence, it outputs the response, sometimes with citations attached.
3. If it can’t, or if the question type triggers Retrieval anyway (recency, specificity, factual claims with low training confidence), the model fans out. That can mean one search or it can mean five or ten parallel queries against different sources. The retrieved content gets summarized into the response, usually with citations.
4. The fallback can also happen mid-answer. A Core Model attempt produces a draft, the model’s own uncertainty triggers Retrieval to validate, and the final response is a blend.
Two things worth flagging here:
- First, retrieval is not the model’s first move. It’s a fallback. The questions that trigger retrieval are the ones the Core Model couldn’t (or wouldn’t) confidently answer alone. That’s a smaller surface than most “GEO” advice assumes, and most of that advice is unknowingly aimed at it.
- Second, the fan-out queries are not your search queries. When the model retrieves, it rewrites the prompt into one or more queries optimized for its retrieval system. You don’t see them. Your SEO is competing on the model’s rewrites, not on the user’s original prompt.
Not Every Citation is Real
Citations come in two flavors, and the distinction is doing a lot of work that most AI-visibility tools ignore.
A decorative citation builds user trust and offers further reading, but it wasn’t actually used to generate the answer. The model produced its response from the Core Model, and then tacked on plausible-looking sources after the fact. This is why you’ll occasionally see citations pointing to 404s, made-up URLs, or pages whose content has nothing to do with the claim being supported. The model invented a credible-shaped source.
A retrieved citation is the real thing: content the model actually fetched at query time and that’s clearly represented in the response.
A note on terminology: In SEO conversations, retrieved citations often get called “grounded” citations. I’ve used that shorthand myself and I’m trying to move away from it so I don’t contribute to the confusion. In AI research, ground has a stricter meaning: connecting a model to factual ground truth, like databases, sensors, or verified records. A web page the model happened to retrieve isn’t ground truth. It can be biased, promotional, outdated, or wrong. Britney has flagged the loose use of “grounding” as a credibility risk for the SEO field, and she’s right. So when I write “retrieved citations” here, that’s what most write-ups (mine included, until recently) have been calling “grounded.”
If you’re analyzing where your brand shows up in AI answers, a citation isn’t proof the source influenced the answer. It’s a starting point, not a conclusion. Tools that score “AI visibility” by citation count without separating decorative from retrieved are reporting a mix of signal and noise, and the ratio shifts model by model and topic by topic.
The practical version: if you only optimize for citations, you may be optimizing for the model’s decoration layer rather than its reasoning layer. Sometimes that’s fine. Sometimes you’re paying for visibility that has zero bearing on what the model actually says about you.
What This Means for AI/LLM Visibility Strategy
Two mechanisms means two distinct optimization surfaces. They aren’t interchangeable, they don’t trade off against each other, and you need both. But you do need to know which one a given tactic is feeding.
Optimizing the Core Model: The Long Game
This is where the durable AI optimization work lives. If your brand, your products, and the sentiment around them are baked into the Core Model, you get stable positioning across millions of prompts. You’re not depending on whether the model decides to retrieve anything on a given day, or on whether the retrieval algorithm changes next quarter.
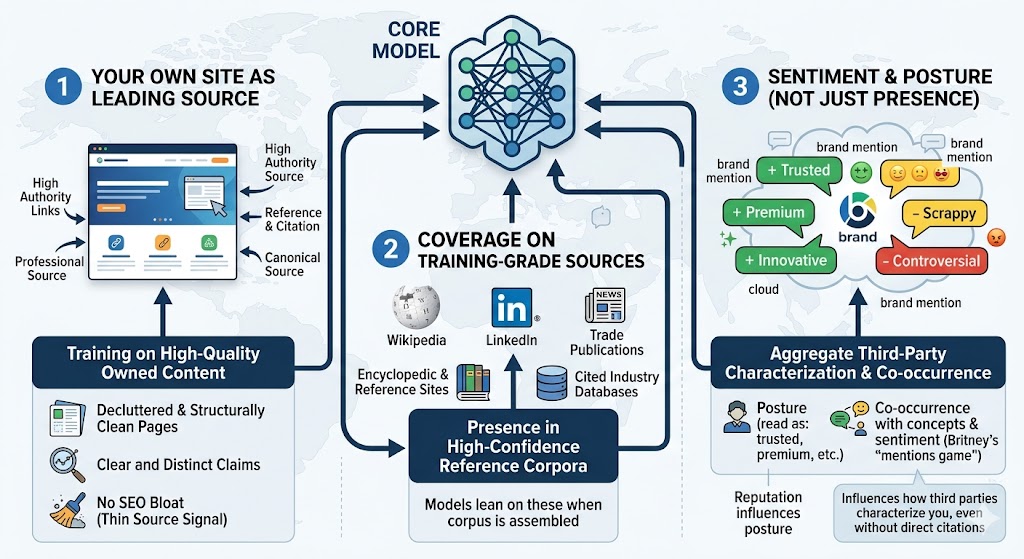
The Core Model gets fed in three main ways:
- Your own site (if treated as a leading source): Models train on the open web. The pages that get included, and weighted, are the pages that other authoritative pages link to, reference, and treat as canonical. That’s why the foundation has to be decluttered, clearly-messaged, structurally clean content. We want our pages to be the kind of pages worth training on, especially as the impact of AI on content creation raises the bar for what qualifies as ‘high-quality.’ Real authority, clear claims, no SEO bloat that signals a thin source.
- Coverage on training-grade sources: Wikipedia. LinkedIn. The established trade publications in your industry. Encyclopedic and reference sites. Well-cited industry databases. These are the high-confidence sources models lean on when their training corpora are assembled. If you’re not in them, you’re not in the Core Model, no matter how much owned content you publish.
- Sentiment, not just presence: The Core Model encodes more than facts. It encodes posture: whether a brand reads as “trusted” or “premium” or “scrappy” or “controversial.” That posture is downstream of how third parties have written about you, in aggregate, on sources the training process weighted. Britney calls this “the mentions game, not the backlinks game.” What the model absorbs is the co-occurrence of your brand with concepts and sentiment, not link equity. Reputation work that influences how third parties characterize you is Core Model work, even when it doesn’t immediately show up as a citation anywhere.
This is slow, compounding work. The payoff: when the next model version ships, your positioning either stays the same or improves. You don’t have to re-litigate it every time the retrieval algorithm changes.
Optimizing for Retrieval: The Quick Wins
Retrieval optimization is closer to traditional SEO. You’re trying to land on the pages the model fetches when it doesn’t already know the answer. Because this layer is so volatile—and varies wildly between ChatGPT, Claude, and Gemini, tracking your presence in AI Overviews and other AI-generated search results is the only way to see what is actually triggering for your brand across the different engines. The catch is that your inclusion is only as stable as the model’s fan-out and search behavior, which means volatility in brand exposure and exposure to whatever sentiment the model gathers on the way.
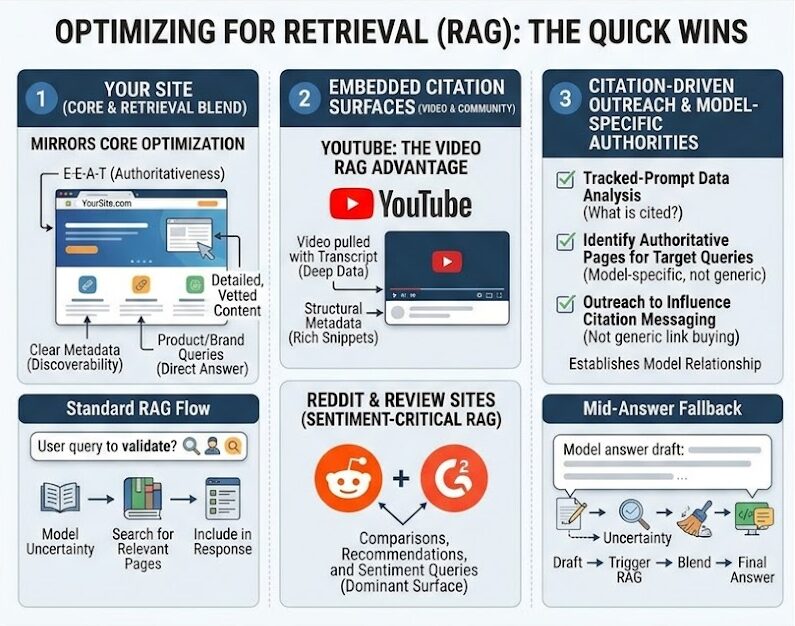
Will and Britney discuss the surfaces where the leverage is right now, and this list is an extension of theirs.
- Your own site: Your site is still a key retrieval source likely to be surfaced for product and brand related queries. The efforts to optimize for retrieval would mirror the efforts to influence the core model… standard E-E-A-T approaches with discoverability, etc..
- YouTube: Video is increasingly embedded as a citation source. Unlike most retrieval surfaces, video gets pulled with its transcript and its structural metadata, so influencer-led content extends reach into AI answers in a way text-only blogs can’t match.
- Review and community platforms: Reddit, G2, and similar platforms are heavily referenced by current models, especially for questions about comparison, recommendation, or sentiment. Sentiment management on these surfaces is no longer optional. For some prompt classes, it’s the only thing the model is retrieving from.
- Citation-driven outreach: Once you have enough tracked-prompt data, you can pull the pages being cited across your target queries and aim outreach at those pages, not at generic high-DA targets. It’s a different list than a traditional SEO link-building list. It’s the list of pages this particular model considers authoritative for these particular questions. You aren’t just trying the legacy begging/buying links approach here, you are hoping to establish a relationship and influence the messaging on the citation and ultimately the way their page is used to develop responses about your brand/services/products.
The earlier caveat still applies. Not every citation reflects content the model actually retrieved. Many are decorative. But even the decorative ones tell you which pages the model might consider relevant, and which pages a curious user is likely to click. Working those pages still pays dividends in conventional SEO, and it pays dividends in the small probability that the next model version takes them more seriously. Nothing wasted.
So, Where Does That Leave Us?
The Core Model is where stable brand positioning is won. Retrieval is where you catch the queries the model can’t answer on its own. A real AI visibility strategy works both surfaces, and it starts by knowing which surface a given tactic is for.
The work that compounds (content worth training on, coverage on sources models actually weight, reputation managed where it matters) is the work most agencies are under-investing in. The feedback loop is slow, and the dashboards don’t show it. The work that flickers (citation counts, today’s retrieval results, the AI Overview that showed up this morning) is the work most agencies are over-investing in, because it’s measurable and C-Suites often demand 3rd party metrics to justify that the effort is working.
Both matter. They just aren’t the same thing, and this distinction can fundamentally shift your AI search and LLMO strategy.
—
*Further reading: Will Critchlow and Britney Muller, LLMs do not rank anything. So what are you optimizing for? at SearchPilot. The framing that prompted this piece. Britney’s “mentions game / not backlinks game” line and her pushback on the loose use of “grounding” in SEO are both great takes that are worth reading directly.
** Images generated with Gemini and provide good overview of concepts, but may contain inaccuracies.