Update: 08/08/2022 — Def. not working as I had expected…
At the moment… Outcome is that
- If you embed a pdf on a page (A), and the pdf is noindexed…
- page A will continue to be indexed … the noindex doesn’t pass through
- the content does not fold into page A … which was expected
- If you embed a pdf on a page (B), and the pdf is noindex, indexifembedded …
- page B will continue to be indexed … cuz why not?
- the content does not fold into page B ….. twitterseo says its because folding a pdf is hard, but I’m not buying that it is more difficult to fold easily readable text than it is text from embedded charts, etc.
- If you have a PDF with noindex, indexifembedded
- Google doesn’t honor indexifembedded… supposedly because its a PDF?
- If you use noindex + indexifembedded, apparently they ignore the noindex and index it anyway
- If you have a PDF with noindex
- This doesn’t get indexed… at least I got one hypothesis right..
Update: 08/02/2022 — Starting to get some preliminary observations, which are not working as I expected.. Join the discussion here..
Created 2 pdf files… added “noindex” x-robots-tag to one and “noindex,indexifembedded” to the other.
…
What do you think happened?— Jake Bohall (@jakebohall) August 2, 2022
In January, 2022, Google announced a new robots tag, indexifembedded on the developers blog. When reading through this documentation, it is not fully clear exactly what this tag does for various types of embedded content… more specifically, we couldn’t find a definitive answer on:
- What is the clear reason for the indexifembedded tag? Is it just to prevent noindex passing through to the embedding page if I host a file that is noindexed, and that file is embedded on an otherwise indexable page?
- Is that the only solution the tag offers? If I add indexifembedded to a noindexed pdf file, or other content where the embedded media would be indexable and served in Google search results.. is that content now indexed somehow?
- Content credit? Does indexible content from an embedded object get attributed to the page embedding it?
When this first came out, I was vaguely interested, but didn’t dive in as I didn’t have practical use case in mind where this would seem to impact any current client sites. Over the last few months, I’ve had a practical use case / cause come up to inspire some questions. Background:
- Website has had large library of pdf files with unique and valuable info for many years
- Website wants better experience for users and creates a page with navigation, other helpful resources/info, etc and embeds pdf into a more useful page.
- Website updated some internal links to point to embedded urls to see if they could stand alone, with unimpressive results
- 150k+ organic visits per month to pdf files, 2k organic visits per month to embed page after 1 year
- Want to transfer traffic/authority/etc to embed page.
After discussing with a large number of SEOs, it was clear there isn’t a consensus on why the indexifembedded tag exists, how to use it, or the impact that it has. The most common thread was the believe that if embedded content has a noindex tag, that the page hosting the embed would be noindexed… and that this tag was created to allow someone to index content without having their page noindexed as a consequence.
In an effort to address my specific practical case above, and to further better understand the impact of this tag, we proposed a very rudimentary test that would check for the following scenario.
Grow with Hive SEO Services
In the ever shift AI-landscape, where Large Language Models and generative search dominate the way people interact with brands, one thing remains true - You need to remain visible in all the right channels. Hive's team of expert SEOs have years of experience adapting to change in the way people search. We'll combine technical SEO expertise, expert content writing, and advanced AI engineering to make sure you stay relevant in the new world of search.
Discover Hive SEO Services- Create 2 pdfs with some nonsensical / unique content
- Post 1 pdf with noindex header and the other with noindex and indexifembedded. This was deployed using a simple cloudflare worker that would insert the appropriate headers for each file, see example at bottom of post.
- Embed these pdfs on two different pages that are open for index/crawling
- Submit these pages to the index, and once indexed, check if they appear in exact match searches for content within the pdf.
If we could pass muster on #2 above, then a proposed solution for our practical use case would be to:
- copy pdfs to new directory and noindex,indexifembedded header
- update embeds to reference new file locations
- redirect all original pdfs to embed URLs.
- 4- wait and see what happens..
So.. we are off to test this out and see what we can find. I’m excited to test this… but wish there was better documentation…. will update this post with results..
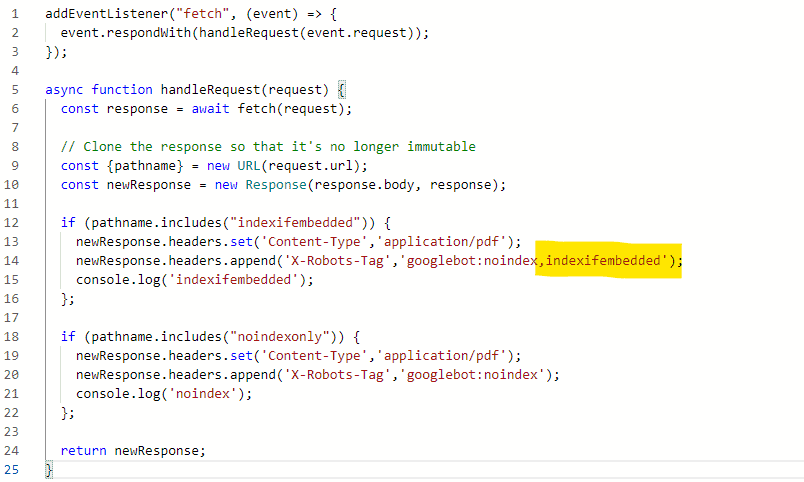
Cloudflare Worker Used to Modify Header Response
Note.. this will likely be updated.. version used for experiment is here.. evolution will be on github
addEventListener("fetch", (event) => {
event.respondWith(handleRequest(event.request));
});
async function handleRequest(request) {
const response = await fetch(request);
// Clone the response so that it's no longer immutable
const {pathname} = new URL(request.url);
const newResponse = new Response(response.body, response);
if (pathname.includes("indexifembedded")) {
newResponse.headers.set('Content-Type','application/pdf');
newResponse.headers.append('X-Robots-Tag','googlebot:noindex,indexifembedded');
console.log('indexifembedded');
};
if (pathname.includes("noindexonly")) {
newResponse.headers.set('Content-Type','application/pdf');
newResponse.headers.append('X-Robots-Tag','googlebot:noindex');
console.log('noindex');
};
return newResponse;
}