It is a growing conception of the SEO world that getting links from highly relevant pages is no longer just valuable, but necessary in order to rank. I am by no means the only SEO to doubt the veracity of these claims (here is Michael Martinez and Julie Joyce on the issue in 2007), but despite their reasoned arguments, the myth continues to persist.
So, I thought it was time to put some data to the test using the same Wikipedia Link Modeling that we had used in past to test theories on Link Depth, Link Proximity and other link diagnostics.
Last year, after SEOMoz’s ground breaking work on the relationship between Latent Dirichlet Allocation and Google rankings, we brought on Andrew Cron, a Ph.D. statistics candidate at Duke University to build our own in-house LDA model. While we now use this in nearly every content writing endeavor, it has also been useful to test out theories about content relevance.
The Plan
The strategy is actually quite simple.
- Get the backlinks of around 50 unique Wikipedia articles and then determine the LDA score of the title of those Wikipedia pages to the content of the backlinking pages.
- Compare a single piece of content to 1000 randomly selected words to determine the random distribution of english language topical relationships
- Observe if Wikipedia backlinking pages generally out-perform random content in terms of relevancy.
The Results
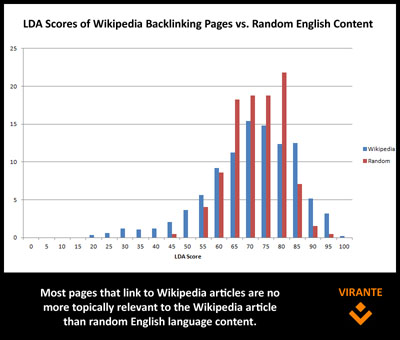
The results were actually quite unimpressive. From what we can see, the overwhelming majority of pages that link to Wikipedia articles share no discernible topical relevance above that of random content to the article they cite.
 The graph above shows the distribution of LDA scores from random content vs. Wikipedia backlinks. As you can see, there is a great drop off in the random scores above an LDA score of 80. A better representation is that of the differentials below.
The graph above shows the distribution of LDA scores from random content vs. Wikipedia backlinks. As you can see, there is a great drop off in the random scores above an LDA score of 80. A better representation is that of the differentials below.
 About 15% of links are relevant enough that they cannot be described by randomness. This seems to stand in stark contrast to any expectation that all links one acquires should be topically relevant to the subject matter of the page. In fact, we actually see a cluster of pages that are distinctively different from the page to which it links. While some of this can be described by very thin content (a surefire way to get a low LDA score is to have almost no content on the page), we find another phenomenon occurs.
About 15% of links are relevant enough that they cannot be described by randomness. This seems to stand in stark contrast to any expectation that all links one acquires should be topically relevant to the subject matter of the page. In fact, we actually see a cluster of pages that are distinctively different from the page to which it links. While some of this can be described by very thin content (a surefire way to get a low LDA score is to have almost no content on the page), we find another phenomenon occurs.
Why People Link
We actually find that this reinforces two reasons why people link out on the web.
- Citation Links: These are links where the webmaster is citing content they have included on their page. You would expect high LDA scores because the writer is merely giving credit to the original source of that content (quoted or paraphrased).

- Descriptive Links: These are links where the webmaster is choosing to link to content rather than write about it. Because the link is offered in lieu of writing out the content, you can expect lower than average LDA scores. The link is there explicitly so the related content does not have to be. It is an alternative to relevant content.
Take Aways
Does this mean you should avoid getting links from related sites? Absolutely not. However, it does mean that you should not give up a link solely because the content is not textually similar to the content on your page. If the link is good for the user, it is good for Google.